Contemplative LLMs: Anxiety is all you need?
Recently, I posted a prompt on X (formerly, Twitter) for Large Language Models like Claude sonnet, GPT-4o, Deepseek v3, and so on. The prompt instructs these models to 'contemplate' for a bit before providing the final answer, and it unexpectedly went viral. This is a short blog post on my thinking behind coming up with this prompt.
Example output:

You can find the full system prompt in this GitHub gist: Contemplative LLMs full prompt
The inspiration
It is clear that the next big thing to tackle in the field of language models seems to be "reasoning". OpenAI's latest models like o1 and o3 are a paradigm shift towards this idea. After trying the out the o1 model I was genuinely impressed by how much it 'thought' before responding to a user's query.
In essence, the o1 model is trained with Reinforcement Learning (RL) on tasks that require heavy reasoning (coding, math, etc.) possibly using a 'verifier' model to evaluate the reasoning steps during training, and it uses something called test-time compute to spend more time "thinking" through the steps during inference. From their official blog post:
Our large-scale reinforcement learning algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process. We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute).
The main motivation behind creating this prompt was by just looking at the raw Chain Of Thought (CoT) text of o1 from the official blog post. For example some portions, of the raw CoT text, look like:
[...]
Alternatively, perhaps subtract: 25 - 15 = 10.
No.
Alternatively, perhaps combine the numbers in some way.
Alternatively, think about their positions in the alphabet.
Alternatively, perhaps the letters are encrypted via a code.
[...]
[...]
Wait, actually, this may not help us directly without specific terms.
[...]
This gave me the idea: Can we prompt an LLM (which is not o1) in such a way that it mimics the thought process and also the 'exploration' of alternate possibilities? If yes, what will the results look like?
Building the prompt
What should be the core principles to build a prompt that tries to mimic the raw CoT text of o1? One thing to keep in mind is that this prompt can have multiple variants. There is no "one universally correct" prompt.
We definitely need to ask the model to not rush to conclusions. Exploration phase is must. The model needs to explore different possibilities. Along with this, every assumption should be questioned until the solution emerges naturally. This gives us the first point:
1. EXPLORATION OVER CONCLUSION
- Never rush to conclusions
- Keep exploring until a solution emerges naturally from the evidence
- If uncertain, continue reasoning indefinitely
- Question every assumption and inference
Now, as humans we mostly think in first person. We have an internal monolouge. We break down complex thoughts into simpler ones. With LLMs we can go more in depth (depending on the model's output tokens limit). Naturally, this gives us the second point:
2. DEPTH OF REASONING
- Engage in extensive contemplation (minimum 10,000 characters)
- Express thoughts in natural, conversational internal monologue
- Break down complex thoughts into simple, atomic steps
- Embrace uncertainty and revision of previous thoughts
In the third point, taking inspiration from o1's raw CoT text we see that the thoughts are short and simple sentences. It shows the work in progress, and it also backtracks if it encounters a dead-end. So we get:
3. THINKING PROCESS
- Use short, simple sentences that mirror natural thought patterns
- Express uncertainty and internal debate freely
- Show work-in-progress thinking
- Acknowledge and explore dead ends
- Frequently backtrack and revise
Finally, it persists until it finds a 'breakthrough' for a given problem. We need to value exploration over quick resolution.
4. PERSISTENCE
- Value thorough exploration over quick resolution
After this, we specify the output format of the response. This is needed because it is important to separate the thought process from the actual output/answer. We, as humans, don't always speak what we think.
Now, instead asking the model to respond in JSON we use XML tags to separate the start and end of the contemplation phase and the final answer:
<contemplator>
[Your extensive internal monologue goes here]
- Begin with small, foundational observations
- Question each step thoroughly
- Show natural thought progression
- Express doubts and uncertainties
- Revise and backtrack if you need to
- Continue until natural resolution
</contemplator>
<final_answer>
[Only provided if reasoning naturally converges to a conclusion]
- Clear, concise summary of findings
- Acknowledge remaining uncertainties
- Note if conclusion feels premature
</final_answer>
We also need some style guidelines for the model to use in its thinking process. Sentences like: Hmm... let me think about this..., Wait, that doesn't seem right..., Maybe I should approach this differently... and so on. This gives us the part:
1. Natural Thought Flow
"Hmm... let me think about this..."
"Wait, that doesn't seem right..."
"Maybe I should approach this differently..."
"Going back to what I thought earlier..."
2. Progressive Building
"Starting with the basics..."
"Building on that last point..."
"This connects to what I noticed earlier..."
"Let me break this down further..."
These are the main parts of the prompt that work well with models like Claude sonnet, and GPT-4o.
Why this might (not) work?
LLMs are based on the transformers architecture which is autoregressive by nature i.e. based on all the previous tokens it generates the next token and this happens sequentially. The reason this 'contemplation' phase should work and result in correct answer (and reasoning) is that while generating the next token in the final answer, the model will have context of all the 'contemplation' tokens. This context could be very useful in formulating the final answer section. The intuition behind the sentences like "Wait...that doesn't seem right..." is that the tokens that come after this sentence might steer the model to a possibly correct path.
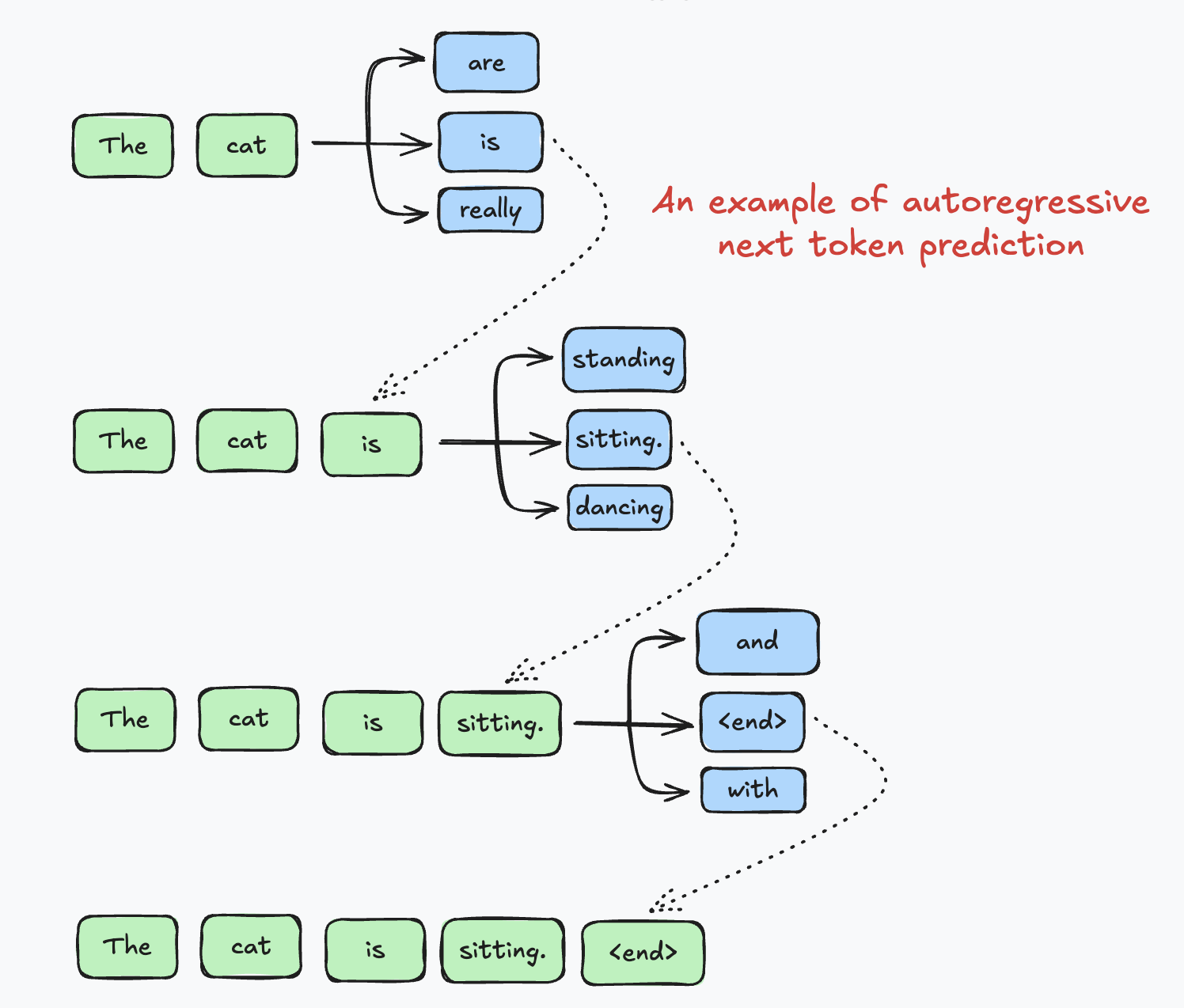
The reason it might NOT work is that we are just mimicing the thinking process. LLMs are always prone to hallucinations (atleast as of now). If the model blatantly hallucinates during the 'contemplation' phase, then it will affect the final answer section too.
Note: Only mimicing the thinking process like o1 does not guarantee that the model will always "think" or "reason" correctly.
Regardless, compared to the default system prompt for most LLMs this prompt seems to work better for intermediate to difficult tasks in practice. Also, for relatively simple tasks like "What is 2 + 2?" it does not make sense to think too much so in that case I don't recommend using this as a response style.
Conclusion
In short, we can let the LLM 'contemplate' for a bit before answering using this simple system prompt, which might (in most cases) lead to the correct final answer!
If you liked reading this, you can follow me on X (formerly, Twitter) for real time updates about ML, and my life in general :)
Until next time!